

Image generation models are evolving rapidly and we can find new image generation tools and updates every day. Well, each models have its strengths, unparalleled in terms of features, and therefore different models have different use cases.
Some focus on creative style and speed while other focus on realism art generation. One such example is Gemini 2.5 Flash Image model which is also known by Nano Banana, extremely hyped for its speed and character consistency output.
In fact, Josh Woodward, VP@GeminiApp and @GoogleAIStudio shared an update on X that over 200 million images have been edited and over 10 million people using Nano Banana are new to the Gemini app.
Additionally, several tech journalists and professionals have praised Nano Banana for its features and capabilities. The Washington Post called it “masterful” at manipulating photos with simple prompts. TechRadar found it superior for character consistency, realism, and image-to-image fusion.
These lot of positive verdict genuinely pointing to one thing that Gemini 2.5 Flash Image model is well-versed trained with reinforcement learning techniques.
!
No more further edo, I will discussing Nano Banana workflow and understand model architecture in detail. So, if you’re have interest learning technologies behind Nano Banana (Gemini 2.5 Flash Image) – read along with me!
Table of Contents
Understanding Workflow Of Gemini 2.5 Flash Image (Nano Banana) Image Generation Model
1. User input the prompt (text/image/edit instructions)
The workflow starts to happen when a user provide the prompt. The prompt can be text-only, text + reference images, or even edit instructions for an existing image.
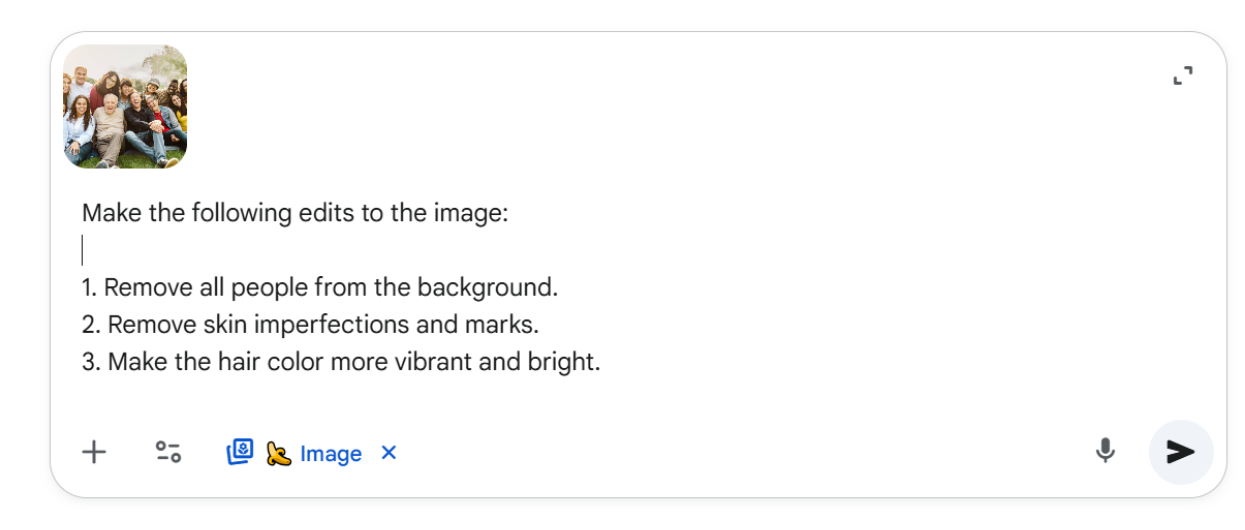
For example, Make the following edits to the image
- Remove all people from the background.
- Remove skin imperfections and marks.
- Make the hair color more vibrant and bright.
The above example incubates text + reference image along with multi-step prompt for editing.
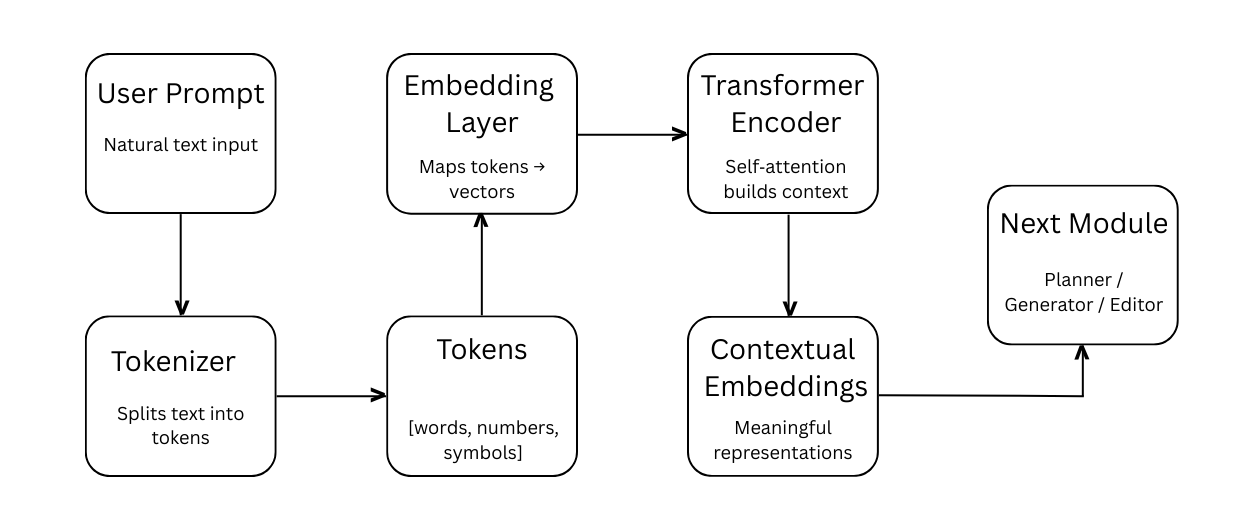
2. Prompt understanding using Gemini (LLM layer with self attention mechanism)
Gemini which is an Large Language Model parses the input through tokenization (like any Transformer model), breaks text into tokens and mapped to embeddings.
It uses self-attention mechanism within the transformer architecture to understand and preserve the word to word meaning accurately.
For example, the given prompt breaks into token (grouping the words, number, and characters) and feeds into the self-attention mechanism to understand the context meaningfully.
3. Multimodal embedding comes into the picture where text encoder and vision encoder happen into vectors
It may sound technical and yes it is because after tokenization and context understanding, they turns into embeddings (a numerical representation often called vector that capture its semantic meaning) which stored in a high dimensional space.
Encoder LLMs are responsible for embedding process and therefore text encoder and vision encoder used to make shared embedding space.
Text encoder LLM converts your prompt into semantic embeddings. On the other hand, Vision encoder LLM encodes identity, colors, layout.
4. Decoder LLM interprets the embeddings and plan how to edit/generate the image
The decoder LLM which is the reasoning brain interprets embeddings. This step is not about understanding embeddings properly but about planning how to edit and generate the image.
For example., If you say “Put a cat in the Colosseum wearing a Roman helmet” → it builds a structured plan: [object=cat][scene=Colosseum][attribute=Roman helmet].
Now the diffusion pipeline kicks in. It starts from noise in latent space (guided step by step by the text-image embeddings). Nano Banana applies identity-preserving embeddings so faces, pets, or objects don’t drift between edits. This feature makes it stronger than MidJourney/Stable Diffusion for multi-turn editing.
5. SynthID Checking & Image Generation
At last, image generation happen and simultaneously SynthID watermark processing the image for safety filters such as violence, NSFW, political misuse, etc.
After these checking done, the final image is show to the user with affected requests given. Users can further enhance the image or make more tweaks and download locally.
Technologies Behind The Nano Banana Image Generation Model
1) Gemini LLM
Gemini 2.5 represents a sophisticated artificial intelligence developed by Google. It possesses the capability to comprehend and produce human language. Furthermore it can discern connections between various forms of information. This includes written words, visual pictures, and even moving images.
Essentially consider Gemini as the central intelligence for Nano Banana. It is the component that processes user requests. It then grasps the surrounding circumstances. This understanding is then conveyed to the visual generation system.
Consequently users can provide straightforward instructions. For instance one might request a photograph be transformed into a vintage painting style. This eliminates the need for complex specific commands. Gemini effortlessly connects everyday language with the creative abilities of artificial intelligence.
2) Encoder-Decoder Self-Attention Mechanism
An artificial intelligence system processes your words in a thoughtful manner. It carefully considers each part of your input. Think of it like someone listening intently to a story. They might mentally revisit sections to grasp every detail. This is similar to how the system operates.
The system first divides your message into understandable segments. It then identifies the most significant pieces of information. Following this the system reconstructs these pieces. This reconstruction allows it to produce a fitting reply.
Therefore the AI does not simply accept your words as they are. It also comprehends the underlying significance. Furthermore it recognizes the connections between different words.
3) Stable Diffusion Architecture
The system known as Stable Diffusion offers a way to generate pictures from written descriptions. Imagine an artist beginning a painting. They do not start with a finished product. Instead the process begins with a canvas filled with random patterns.
This is similar to a blurry starting point. The system then works through this randomness. It makes small adjustments over time. This gradual refinement leads to a clear picture. This approach enables the artificial intelligence to create images that are very lifelike and full of detail.
A key strength lies in its step by step creation. It does not simply produce an image all at once. Rather it carefully develops the image through distinct phases. This mirrors an artist’s journey from initial sketches to a polished artwork.
4) SynthID Checking
SynthID provides a discreet method for discerning images produced by artificial intelligence. Consider it a concealed mark within each AI created picture.
This mark remains unseen by people. However specific instruments can find it later. This capability holds significant value in our current environment. False or changed pictures can proliferate rapidly.
Utilizing SynthID allows organizations and individuals to track an image’s AI source. This facilitates distinguishing genuine photographs from those made by machines. It also assists in lessening the danger of incorrect information or improper application.
!
Key Learning
Gemini 2.5 Flash Image (Nano Banana) isn’t just another AI image generator, it combines the intelligence of Gemini with diffusion workflows and SynthID safeguards to deliver creative, consistent, and safe visuals. In the end, sharing my thoughts and learning on Gemini 2.5 Flash Image Generation Model.
- Nano Banana is a go-to creative suite for anyone looking to create stunning visuals and edits.
- It’s AI Model is intelligent at generating consistent characters and attention to details.
- The Nano Banana Image generation model is better than Flux Kontext and Midjourney.
Frequently Asked Questions
What is identity preserving embeddings?
Identity preserving embeddings act as a digital footprints that protect the specific subject in AI edits. For example, if you want to change the outfit of the character. It let the AI make creative changes while keeping your identity consistent and recognizable across multiple generations or edits.
How to use Nano Banana In Gemini?
The easiest way to use Nano Banana is through Gemini AI where both model 2.5 Flash and 2.5 Pro support its iteration model for image generation.
Is Nano Banana Better Than GPT-5?
In most scenario, Nano Banana understand the context at speed while GPT-5 had a focused view and takes longer time in image generation. The new iteration excels at producing natural, creative result without altering facial and looks.
What are the technologies supporting Nano Banana?
Google new Image Generation tool supports Large Language Model (LLM), Transformer-based architecture with self attention mechanism, diffusion model ike CLIP, and SynthID watermark for unusual detections and filters.
Disclaimer: The information written on this article is for education purposes only. We do not own them or are not partnered to these websites. For more information, read our terms and conditions.
FYI: Explore more tips and tricks here. For more tech tips and quick solutions, follow our Facebook page, for AI-driven insights and guides, follow our LinkedIn page.
Top 10 News
-
01
Top 10 Deep Learning Multimodal Models & Their Uses
Tuesday August 12, 2025
-
02
10 Google AI Mode Facts That Every SEOs Should Know (And Wha...
Friday July 4, 2025
-
03
Top 10 visionOS 26 Features & Announcement (With Video)
Thursday June 12, 2025
-
04
Top 10 Veo 3 AI Video Generators in 2025 (Compared & Te...
Tuesday June 10, 2025
-
05
Top 10 AI GPUs That Can Increase Work Productivity By 30% (W...
Wednesday May 28, 2025
-
06
[10 BEST] AI Influencer Generator Apps Trending Right Now
Monday March 17, 2025
-
07
The 10 Best Companies Providing Electric Fencing For Busines...
Tuesday March 11, 2025
-
08
Top 10 Social Security Fairness Act Benefits In 2025
Wednesday March 5, 2025
-
09
Top 10 AI Infrastructure Companies In The World
Tuesday February 11, 2025
-
10
What Are Top 10 Blood Thinners To Minimize Heart Disease?
Wednesday January 22, 2025
Related Posts
Artificial Intelligence
What Is AI Transcription For Businesses And How Does It Work...
By: Neeraj Gupta, Sun February 22, 2026
In today’s fast-paced digital economy, businesses produce immense amounts of..

Artificial Intelligence
What Is Consistent Character AI and Why It Matters In Genera...
By: Neeraj Gupta, Sat February 21, 2026
Generative AI has progressed at an astonishing rate. From text-to-image systems..

Artificial Intelligence
How To Build Chatbot App Development For Customer Service (S...
By: Neeraj Gupta, Sat February 21, 2026
Customer service expectations have progressed faster than most support..

Artificial Intelligence
AI In FinTech, Healthcare, And IT Consulting: Use Cases, Cha...
By: Neeraj Gupta, Sun February 15, 2026
Organizations across industries face a general defiance, data overload, and..

Artificial Intelligence
AI Automation For Marketing And Lead Generation: Common Chal...
By: Neeraj Gupta, Sat February 14, 2026
Businesses and organizations today are under increasing pressure to generate..

Artificial Intelligence
Integrating AI And Automation Into Your Digital Marketing Fu...
By: Ankita Sharma, Wed February 11, 2026
The rapid evolution of artificial intelligence has changed how businesses..
Subscribe
0 Comments