

The very first multimodal model seen in 1997 by IBM ViaVoice that capable to process and connect information from two modalities (Audio and Text) and has been used for use cases like speech-to-text and text-to-speech scenarios.
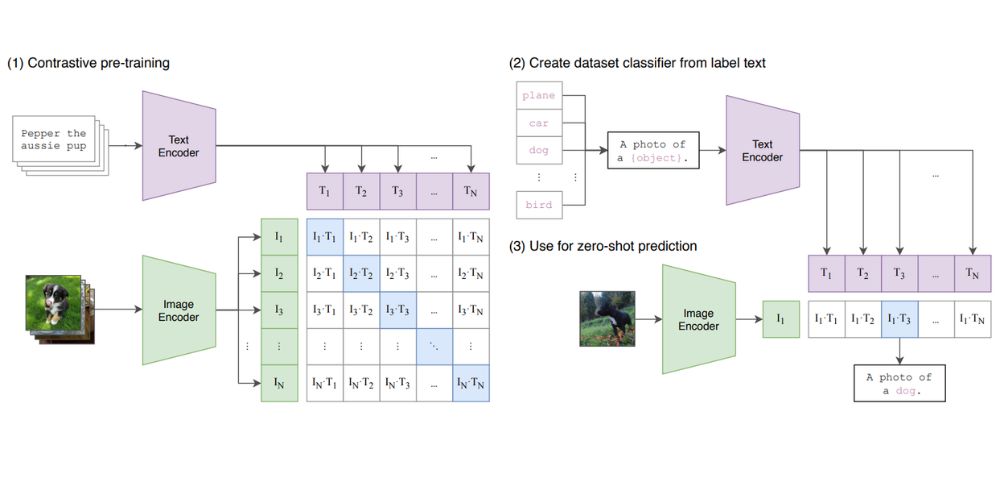
Then between 2001 to 2019, modern neural multimodal models has been developed that capable to process and connect information from new modalities (Image + Text) and has been widely used for use cases like generating images from text. Few popular examples include VQA Models, OpenAI Clip, and DALL-E.
With ongoing enhancements, the latest multimodal models are GPT-4o, GPT-5, and Genie 3 that support various modalities (Text + Image + Audio + 3D) to generate interactive output.
According to research, the multimodal AI market will grow by 35% annually to USD 4.5 billion by 2028. This means the use of multimodal AI models will increase and expand its applications to more industries.
In this blog, I have discussed the best multimodal models to this date along with use cases, current challenges, and future trends.
Table of Contents
What Is Multimodal Model?
A multimodal model is an advanced deep learning model capable of understanding and processing multiple types of data such as text, images, audio, video, and 3D to generate a wide range of outputs effectively.
For example, You upload a photo of a math problem on paper and ask, “Can you solve this?”
The integrated model reasons about the problem using its language model capabilities and output as writing the solution with diagram.
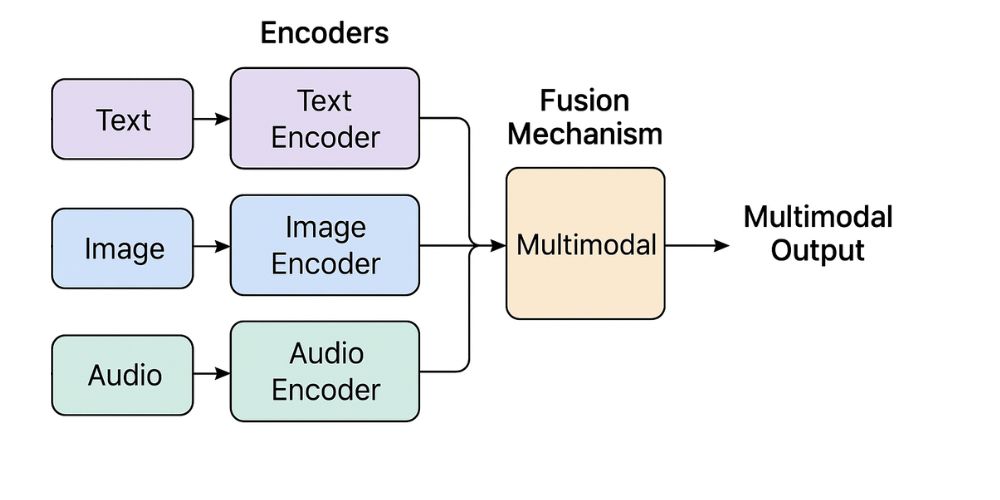
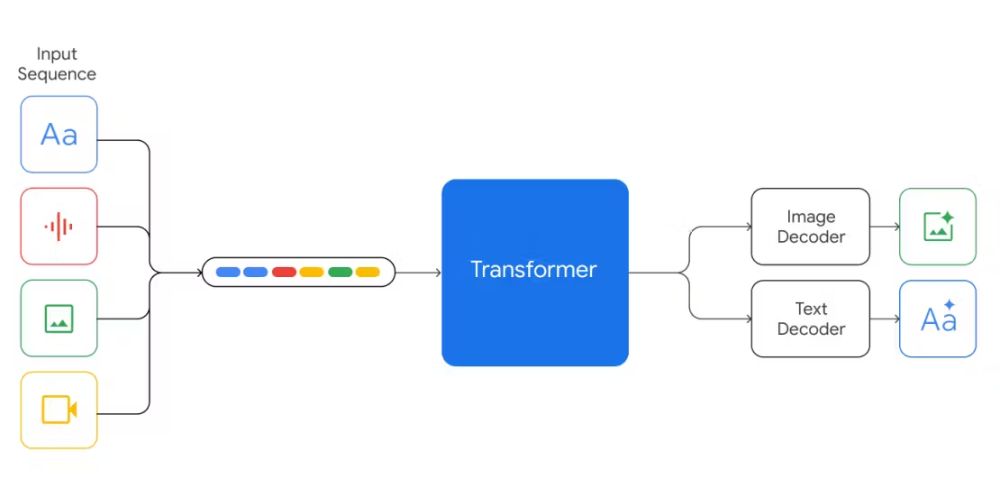
As we speak of multimodal models, it uses encoders and decoders for understanding input, processing, and generating output. Let’s learn about them in detail in the next section.
How Multimodal AI Models Works?
A fully multimodal model architecture includes an encoder, a fusion mechanism, and a decoder. Almost all modern multimodal models work in the following manner, but the way they use them depends on the model’s design and purpose.
1. Encoders
Convert raw input (text, image, audio, video) into a numerical representation (vector or embedding) that the model can understand. For each data type, distinct encoders is used and hence vectors are developed separately.
Example:
In CLIP by OpenAI the text encoder turns “A cute brown dog” into a vector of numbers. The image encoder turns a dog photo into another vector of numbers.
For each modalities, distinct encoders are used for accurate vector transformation. Following encoder types are utilized for the best results.
- Image Encoders: To convert image, Convolutional neural networks (CNNs) are used that can convert image pixels into feature vectors with higher accuracy.
- Text Encoders: For converting text input, transformer based encoders are used that transformed into embeddings. Generative Pre-Trained (GPT) is a popular transformer mostly used.
- Audio Encoders: To convert audio input, Wav2Vec2 encoder is popularly used which convert critical patterns like rhythm, tone, and context into vectors.
- Video Encoders: Various encoders such as TimeSformer, Video Swin Transformer, Video MAE, and X-CLIP used to convert video input into frame for spatial features and further into vector embeddings so the model can process and reason about it.
2. Fusion Mechanism
The fusion layer takes the embeddings from each encoder and combines them into a unified representation. This makes easier for decoder to generate required output.
Example:
In Flamingo (by DeepMind) the fusion module uses cross-attention layers so the text can attend to relevant image parts when answering a question like “What is the man holding in the picture?”
The above example follow attention-based method, in which it use the transformer architecture to convert embeddings from multiple modalities into a query-key-value structure and allow models to understand relationships between embeddings for context-aware processing.
Other than attention-based fusion mechanism, there are two more method used which is discussed below.
Concatenation: It is a straightforward fusion technique that simplify joining embeddings from different modalities before feeding to the next layer.
Dot-Product: This method based on element-wise multiplication of feature vectors from different modalities. It measuring similarity or aligning modalities, often used in models like CLIP for text–image matching.
3. Decoders
Finally, the last component of multimodal models architecture in which decoders takes unified vectors from fusion mechanism to produces the desired output in one or more modalities. It can generate text, images, audio, or even structured data.
Example:
In GPT-4o, you can give it both audio and image inputs, and the decoder can output text (a description), or even generate speech back.
Following decoder types are used to facilitate the decoder algorithm:
- Recurrent neural network (RNN): It is used for sequential outputs like text (e.g., in older seq2seq models or speech generation).
- Convolutional Neural Networks (CNN): It is used when the output is spatial, like generating images or segmentations.
- Generative Adversarial Network (GAN): It uses two neural networks to generate realistic data by having a generator act as the decoder.
10 Popular Multimodal Models With Use Cases
Now you have understanding of multimodal models working, let’s look at the latest and top multimodal AI models as of now.
1. GPT-5
A major leap beyond GPT-4, GPT-5 offers unified multimodal understanding of text, images, audio, and video, with a massive context window (up to ~400K tokens) and advanced reasoning, memory, personalization, and “built-in thinking” capabilities.
Use Cases: Rich conversational agents, complex coding workflows, long-form document analysis, real-time multimodal interaction, and adaptive agentic tool use.
2. Genie 3
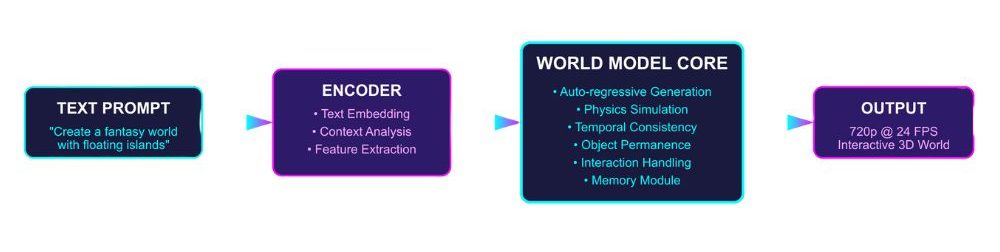
Generates fully interactive 3D worlds at 720p/24 fps from simple prompts, with dynamic environmental responses though memory currently limited to the last few minutes.
Use Cases: Real-time simulations, VR/AR experiences, educational environments, and AI-driven world modeling or training.
3. ImageBind

Creates a shared embedding space across six modalities (image, video, audio, text, depth, thermal, sensor/IMU data) without supervised alignment.
Use Cases: Cross-modal retrieval, zero-shot classification, sensor fusion, embodied perception (e.g., robotics/IoT), and multimodal search.
4. Gemini 2.5 Pro
A highly capable “thinking” model with native support for text, image, audio, video, code, and long 1M token context, excelling at complex coding, reasoning, and multimodal comprehension.
Use Cases: Technical content generation, multimodal reasoning, interactive visual/dialogue applications, and analyzing large mixed-format datasets.
5. Meta’s Llama 4
Open-weight MoE models tailored for multimodal tasks with long context (10 million tokens), efficient performance, and reduced bias.
Use Cases: Multimodal academic research, open-source development, scalable AI tools, and edge deployment.
6. Qwen Series
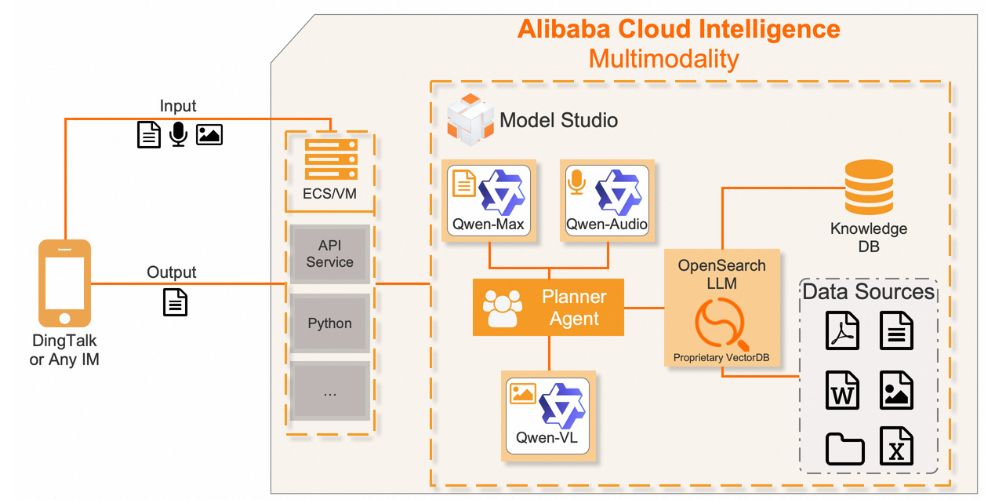
Qwen 2.5-Omni processes text, image, audio, and video and can output text and natural speech via an end-to-end “Thinker-Talker” architecture with time-aligned embeddings (TMRoPE). Scaled-down variants offer real-time performance on standard hardware.
Use Cases: Multimodal assistants, live streaming contexts, on-device voice/text interaction, and integrated video-audio reasoning.
7. LLaDA-V
A novel diffusion-based multimodal large language model leveraging visual instruction tuning, departing from traditional autoregressive designs.
Use Cases: Visual instruction following, creative generation tied to language, cross-modal creative workflows, and research-oriented multimodal experimentation.
8. DALL·E 3
The next-generation text-to-image model with realistic and detailed output, tightly integrated with ChatGPT and optimized for instruction following and text rendering.
Use Cases: Creative art generation, concept illustration, prompt-driven imaging, and content creation workflows embedded in conversational tools.
9. Flamingo
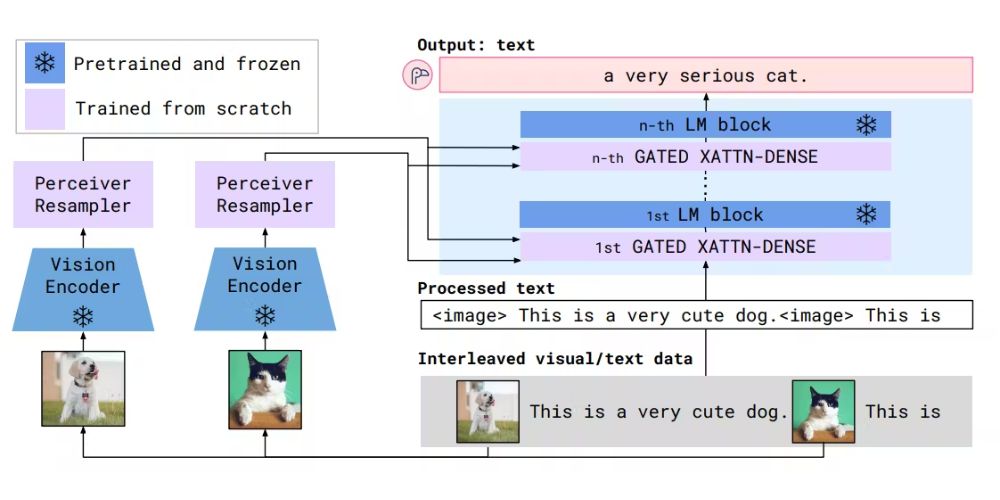
One of the earliest visual-language models capable of processing interleaved text, images, and even video frames in sequence for few-shot reasoning and flexible Q&A.
Use Cases: Visual question answering, few-shot learning for image+text tasks, and dynamic visual dialogue.
10. Claude 3.5
Top-tier, safety-focused LLM family (Haiku, Sonnet, Opus) with improved multimodal (text + images) reasoning, massive context windows, agentic tool use, and novel “artifact” workspace features.
Use Cases: Complex document and visual data analysis, safe agentic workflows, coding and logic tasks, enterprise-grade summarization, enhanced multimodal interaction.
Challenges In Multimodal Models
Huge Data Availability: Precisely data scarcity or imbalance is often the challenge. While multimodal models need massive, diverse datasets, high-quality paired data can be hard to obtain, expensive, and cumbersome.
Extensive Resource Development: Training and running multimodal models demands significant computational power, memory, and storage, plus specialized hardware such as TPUs or AI GPU for productivity.
Bias Amplification: If the training data contains biases, the model can inherit and even amplify them when generating outputs, especially across multiple modalities.
Timnit Gebru, an Ethiopian-born computer scientist said “The only way to make sure that machine learning models are fair and unbiased is to make sure that the data they are trained on is fair and unbiased.”
While human are in the loop reviews to detect biases in model output, several AI-powered tools such as IBM AI Fairness 360 and Microsoft Fairlearn are helping in data audits to identify imbalance or harmful patterns early.
Future Of Multimodal Models
AI Models Auditing AI Models: More independent AI auditor models are developing with advanced capabilities to check for bias and harmful outputs in other AI systems. For example, large companies like Google and Anthropic are testing AI watchdog systems for model output fairness.
Explainable and Interpretable AI: An intelligence system that explain why it made a certain decision, including showing which data influenced it shaping the curve of multimodal models responses effectively.
Privacy-Preserving Learning: Training AI without centralizing sensitive user data, while still ensuring fairness checks across distributed datasets. For example, Healthcare AI using federated learning to balance data from hospitals worldwide.
!
Multimodal Models: Key Takeaway
With voyage, multimodal models are transcending quality outputs in various forms. Reducing the time in quantifying data and creating cognitive outputs for real use cases are the biggest benefits of multimodal models.
With current challenges prevailing in the cosmos of deep learning models, positive use of data generated by these models are opulent. In the end, it is advised to be vigilant about the potential for machine learning models to exhibit bias and unfairness.
That’s all in this blog. Thanks for reading 🙂
Frequently Asked Questions
What are modalities?
Modalities are data types AI can process, such as text, images, audio, video, or sensor data. They’re like different languages of information.
Can multimodal models understand multiple data types?
Yes. They process and connect two or more modalities, linking related information across text, images, audio, video, etc.
What are the limitations of multimodal models?
They face data imbalance, high computational needs, alignment errors, limited input capacity, and potential bias amplification across modalities.
Where multimodal AI models best suitable for?
Medical diagnostics, tutoring, customer support, content creation, surveillance, and e-commerce search.
Disclaimer: The information written on this article is for education purposes only. We do not own them or are not partnered to these websites. For more information, read our terms and conditions.
FYI: Explore more tips and tricks here. For more tech tips and quick solutions, follow our Facebook page, for AI-driven insights and guides, follow our LinkedIn page.
Top 10 News
-
01
Top 10 Deep Learning Multimodal Models & Their Uses
Tuesday August 12, 2025
-
02
10 Google AI Mode Facts That Every SEOs Should Know (And Wha...
Friday July 4, 2025
-
03
Top 10 visionOS 26 Features & Announcement (With Video)
Thursday June 12, 2025
-
04
Top 10 Veo 3 AI Video Generators in 2025 (Compared & Te...
Tuesday June 10, 2025
-
05
Top 10 AI GPUs That Can Increase Work Productivity By 30% (W...
Wednesday May 28, 2025
-
06
[10 BEST] AI Influencer Generator Apps Trending Right Now
Monday March 17, 2025
-
07
The 10 Best Companies Providing Electric Fencing For Busines...
Tuesday March 11, 2025
-
08
Top 10 Social Security Fairness Act Benefits In 2025
Wednesday March 5, 2025
-
09
Top 10 AI Infrastructure Companies In The World
Tuesday February 11, 2025
-
10
What Are Top 10 Blood Thinners To Minimize Heart Disease?
Wednesday January 22, 2025
Related Posts

Top 10
10 Google AI Mode Facts That Every SEOs Should Know (And Wha...
By: Bharat Kumar, Fri July 4, 2025
After the release of AI Overviews, Google recently launched “AI Mode” in..

Top 10
Top 10 visionOS 26 Features & Announcement (With Video)
By: Bharat Kumar, Thu June 12, 2025
In summary: The visionOS 26 features photorealistic personas, spatial scenes,..

Top 10
Top 10 Veo 3 AI Video Generators in 2025 (Compared & Te...
By: Bharat Kumar, Tue June 10, 2025
Veo 3 AI videos are everywhere! Whether on social media, filming sector, and..

Top 10
Top 10 AI GPUs That Can Increase Work Productivity By 30% (W...
By: Bharat Kumar, Wed May 28, 2025
Entities such as Industrial Automation, Chip Design, Computer Vision, and Cloud..

Top 10
[10 BEST] AI Influencer Generator Apps Trending Right Now
By: Bharat Kumar, Mon March 17, 2025
AI models aka generative AI is getting stronger day by day. By far, examples..

Top 10
The 10 Best Companies Providing Electric Fencing For Busines...
By: Ankita Sharma, Tue March 11, 2025
When it comes to securing a business, an electric fence is one of the most..
Subscribe
0 Comments